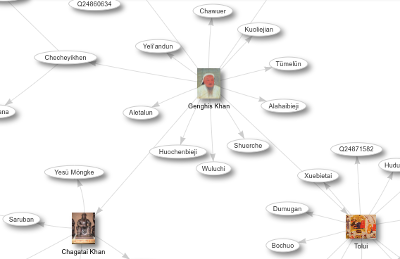
Last month I promised that I would dig further into the Wikidata data model, its mapping to RDF, and how we can take advantage of this with SPARQL queries. I had been trying to understand the structure of the data based on the RDF classes and properties I saw and the documentation that I could find, and some of the vocabulary discussing these issues confused me–for example, RDF is about describing resources, but I was seeing lots of references to entities, which can mean slightly different…
I’ve written so often about DBpedia here that a few times I considered writing a book about it. As I saw Wikidata get bigger and bigger, I kept postponing the day when I would dig in and learn more about this Wikipedia sibling project. I’ve finally done this, starting with a few basic steps and one extra fun one:
Since I wrote “Experience in SPARQL a plus” about SPARQL appearances in job postings almost three years ago, I still find myself pointing people to it to show them that SPARQL is not some academic theoretical thing but a popular tool in production use at well-known companies.
When I wrote the blog posting My SQL quick reference last month, I showed how you can pass an SQL query to MySQL from the operating system command line when starting up MySQL, and also how adding a -B switch requests a tab-separated version of the data. I did not mention that -X requests it in XML, and that this XML is simple enough that a fifteen-line XSLT 1.0 spreadsheet can convert any such output to RDF.
I knew that emojis have Unicode code points, but it wasn’t until I saw this goofy picture in a chat room at work that I began to wonder about using emojis in RDF data and SPARQL queries. I have since learned that the relevant specs are fine with it, but as with the simple display of emojis on non-mobile devices, the tools you use to work with these characters (and the tools used to build those tools) aren’t always as cooperative as you’d hope.
I’ve been hearing more about the Blazegraph triplestore (well, “graph database with RDF support”), especially its support for running on GPUs, and because they also advertise some degree of RDFS and OWL support, I wanted to see how quickly I could try that after downloading the community edition. It was pretty quick.


{kind=link}