Hey CNN, SPARQL isn't so difficult.
And like any programming language, it doesn't have to be convoluted.
In the December 17th cnn.com/technology article Making sense of the ‘semantic Web’, Steve Mollman wrote:
And like any programming language, it doesn't have to be convoluted.
In the December 17th cnn.com/technology article Making sense of the ‘semantic Web’, Steve Mollman wrote:
Or consider it a lazy semweb wish.
I’ve been looking for a SPARQL endpoint that provides new data fairly regularly—not just new triples to query, but data that is new to the world, such as from a stock ticker feed. If the RDFa on digg.com pages was accumulated in a database that could be queried as a SPARQL endpoint, that would certainly qualify, and it would be fun to play with.
A nice new feature of Pellet 2.0.
The open-source program Pellet is described as an OWL reasoner, but I’ve used it mostly as a SPARQL engine that happens to understand OWL. So, for example, if I have RDF that says “Loretta’s spouse is Leroy and spouse is a symmetric property,” but the data makes no mention of Leroy’s spouse, and I ask Pellet “who is Leroy’s spouse,” it can give me the answer.
A little demo.
In the first project I did with SPARQL, D2RQ, and MySQL I used D2RQ to pull all the relational data into a disk file and then queried that after adding some OWL-based metadata. D2RQ does let you execute SPARQL queries against a live relational database, instead of dumping data to a file and querying that, so I wanted to see the effects for myself. This would work better as a live demo, but you could think of it as a script for one.
Or, as the SQL people call it, doing outer joins.

Using SPARQL to answer a few questions that IMDB won't help much with.
Last week I mentioned that the Linked Movie Database SPARQL endpoint would be fun to play with, and it has been. I used my spreadsheetSPARQL interface to send the following queries to their http://sparql.linkedmdb.org:2020/linkedmdb SPARQL endpoint.
And then sort it, graph it, create new calculations... do all that stuff people do with spreadsheets.
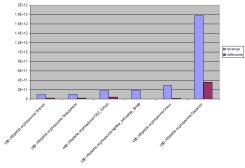
Asking about tables and columns and doing a simple join.
In an earlier project I did querying relational data with SPARQL, I wanted to demonstrate how adding OWL metadata made it possible to answer useful queries that couldn’t have been answered with just the original data. I did this using two simple databases of one table each, but recently, while helping someone who was also using the D2RQ interface to provide access to some relational data, I decided to get more comfortable with using SPARQL to query data from multi-table relational…

Bob DuCharme's weblog, mostly on technology for representing and linking information.

Atom feed (summarized entries)
RSS 2.0 feed (full entries)