
I think that RDF has been very helpful in the field of Digital Humanities for two reasons: first, because so much of that work involves gaining insight from adding new data sources to a given collection, and second, because a large part of this data is metadata about manuscripts and other artifacts. RDF’s flexibility supports both of these very well, and several standard schemas and ontologies have matured in the Digital Humanities community to help coordinate the different data sets.
Unrelated to RDF, in late 2020 a project at Carnegie Mellon University released the The Index of Digital Humanities Conferences. As the project’s home page tells us, “Browse 7,296 presentations from 500 digital humanities conferences spanning 61 years, featuring 8,651 different authors hailing from 1,853 institutions and 86 countries”. These numbers have gone up since the original release of the project. The About page and Scott Weingart’s blog post about the project give more good background.
The presentation abstracts, along with the connections to their presenters and their affiliations, are a gold mine for Digital Humanities research. One of the project’s main menus is Downloads, which lets you download all the data used for the project. The “Last updated” message on that page gives me the impression that they update it several times a week, if not every day. The “Full Data” zip file that you can download from there has CSV files of all the tables in the project’s database.
According to the project’s Colophon, they store their data in PostgreSQL and built the interface with Django. I can’t blame them for storing the data as a relational database instead of RDF, precisely because tools like Django and Ruby on Rails make it so easy to generate nice websites from relational data.
Of course, though, I converted it all to RDF, so I’m going to describe here how I converted it—or rather, how I built a process to convert it, because I wanted an automated system that could easily be re-run when the CSV data to download gets updated. My next posting will describe the cool new things I could do with the data once it was in RDF, because “why bother” is an important question for any such project. Here’s a preview to whet your appetite:
- Easier addition of new properties that only apply to a few instances of some classes
- Linking to other data sets out there (Linked Data!)
- Easy federation and integration of new data
- Inferencing: finding new facts and connections
I put everything necessary to do the conversion and enhancements on github.
I could have loaded the CSV files into a locally running relational database and then used D2RQ as an intermediary layer to treat the relational data as triples. When the Index of Digital Humanities Conferences releases an updated version of their data, though, clearing out the relational data tables and then reloading the updated tables would have been a lot more trouble then just running the short scripts that I wrote, especially if the structure of any of those tables had evolved. And, part of the fun of the conversion was moving beyond the original model to take advantage of relevant standards for easier connection to other projects.
Converting the data
There were two reasons that I wanted the ability to re-run my set of scripts and queries to accommodate updated versions of the data. “Updated versions” could mean that some tables of data had new rows or revised rows, but I wanted to be able to handle new tables and columns as well. If the data models evolve, I want my output triples to reflect this evolution. (This has already paid off. When I first wrote up my notes on this conversion, the Index of Digital Humanities Conferences project had 22 tables, and now it has 23, and I did not need to revise any of my scripts to include the new table’s data.)
With three of the tables loaded into spreadsheets we can see how one table defines the connections between data in the other two the relational way:
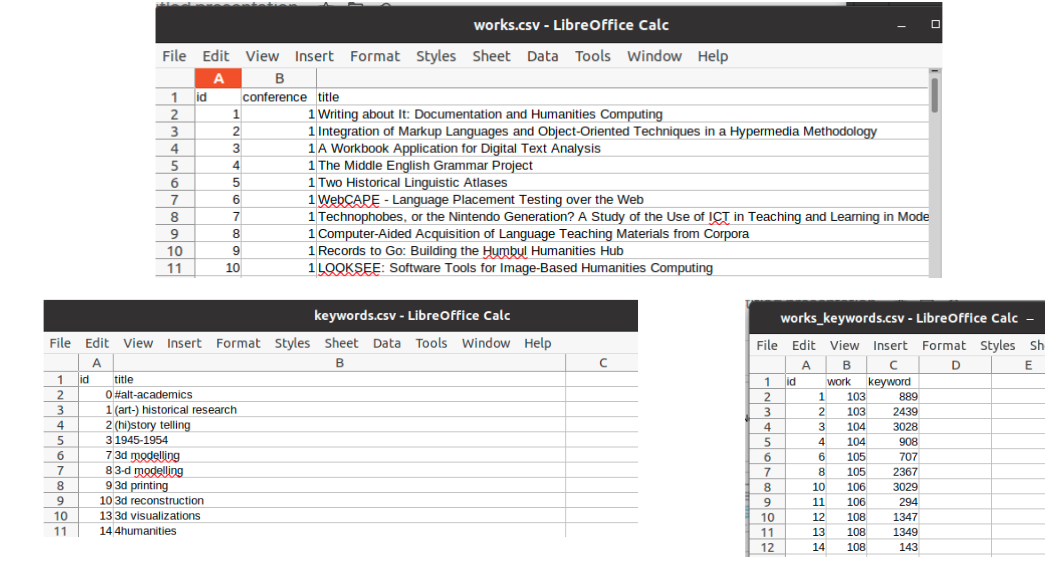
The works_keywords.csv table currently has 13,730 rows. As you can see above, rows 2 and 3 of that spreadsheet tell us that the keywords with IDs 889 ("ead") and 2439 (“sgml-encoding”) have been assigned to work 103, “What’s Interesting for Humanities Computing About Whitman’s Poetry Manuscripts?” This database has nine tables whose sole job is recording relationships between other tables like works_keywords does for the works and keywords tables. (As you’ll see, RDF does a better job of expressing such relationships.)
I used the open source tarql tool to convert all the tables to RDF. Here are some excerpts from the initial conversion:
# from keywords.ttl
<http://rdfdata.org/dha/keyword/i889>
rdf:type dha:Keyword ;
dha:id "889" ;
dha:title "ead" .
# from works.ttl
<http://rdfdata.org/dha/work/i103>
rdf:type dha:Work ;
dha:id "103" ;
dha:conference <http://rdfdata.org/dha/conference/i2> ;
dha:title "What's Interesting for Humanities Computing About Whitman's Poetry Manuscripts?" ;
dha:work_type "3" .
# from works_keywords.ttl
<http://rdfdata.org/dha/works_keywords/i1>
rdf:type dha:works_keywords ;
dha:id "1" ;
dha:work <http://rdfdata.org/dha/work/i103> ;
dha:keyword <http://rdfdata.org/dha/keyword/i889> .
To convert whatever CSV files happened to be in the downloaded zip file, my makeQueries.pl perl script reads all of the CSV files that it finds in the dh_conferences_data subdirectory and:
- If a file has no underscore in its name and is therefore not a list of relationships, the perl script uses a proper-cased singular version of the file’s name as a class name for the data it contains—for example, “Work” for the data in
works.csv. - Creates the query that will drive tarql’s conversion of the CSV file.
makeQueries.plreads the property names from the CSV’s first line and uses them to create a SPARQL CONSTRUCT query that creates an instance of the class whose name it identified in the previous step. Each data row’s ID value (with an “i” prefix added) is used as the local name of the URI that represents that row’s resource. This gives the first work listed (“Writing about It: Documentation and Humanities Computing”) a URI ofhttp://rdfdata.org/dha/work/i1, and the 103rd one, which is shown above, a URI ofhttp://rdfdata.org/dha/work/i103. - Writes the query to the
dh_conferences_sparqlsubdirectory with the same filename as the input CSV file and an extension ofrq. - Writes a line to standard out that tells tarql to read this new SPARQL query file, run it, and put the output in the
dh_conferences_rdfsubdirectory in a file with the same name as the query and an extension ofttl. The directions with the script say to redirect its output of all of these tarql calls to a shell script, so when the perl script is done you can run that shell script to do the actual conversion of all that CSV to RDF.
The makeQueries.pl perl script also has an array of foreignKeyFields so that it knows that when a line from one CSV file is referencing an instance of data in another, it should reference it with a URI. (Knowledge graphs!) So, for example, a value of “1” for a work’s conference (The Joint International Conference of the Association for Literary and Linguistic Computing and the Association for Computers and the Humanities, in Glasgow) is turned into the appropriate URI so that the triple about the “Writing about it” paper’s conference is this:
<http://rdfdata.org/dha/work/i1> dha:conference <http://rdfdata.org/dha/conference/i1> .
If the data model of the relational input data did include a new column of foreign key references, this would require a slight adjustment to the perl script to add that to this foreignKeyFields array.
Making the RDF better than the relational data
Once you have data as triples—any triples—you can use SPARQL CONSTRUCT queries to improve that data.
Using standards instead of ad-hoc namespaces
My conversion script puts a lot of resources in namespaces built around my domain name rdfdata.org. When possible, I’d rather that they use standard namespaces. For example, the script above created this in keywords.ttl:
<http://rdfdata.org/dha/keyword/i2641>
rdf:type dha:Keyword ;
dha:id "2641" ;
dha:title "tei encoding" .
If we’re using keywords to assign subjects to works, I’d rather store information about those keywords using the SKOS standard, so my keywords2skos.rq SPARQL query turns the above into this:
<http://rdfdata.org/dha/keyword/i2641>
rdf:type skos:Concept ;
skos:inScheme dha:keywordScheme ;
skos:prefLabel "tei encoding" .
Note that it’s not actually converting the http://rdfdata.org/dha/keyword/i2641 resource, but just adding new triples about it in the SKOS namespace. These triples are stored separately from the original, so we don’t have to load originals into a triplestore when we use this data in an application.
The conference and abstract data also assigned topics to the various papers, so I did a similar conversion with them, storing them in the SKOS dha:topicScheme scheme instead of the dha:keywordScheme one shown above that I used for keywords.
If I was creating a serious production application, I could take this further. For example, instead of using the property http://rdfdata.org/dha/ns/dh-abstracts/title to reference the abstracts’ titles, I could use http://purl.org/dc/elements/1.1/title, and there is probably an ontology for conferences out there that has defined some of these other properties. (The schema.org Event class looks like it could cover a lot of the latter.)
Improving the links between resources
As we saw above, the works_keywords.ttl RDF file that this process creates from the works_keywords.csv data ends up with triples like this, which tells us that works_keywords row i1 represents a link from work i103 to keyword i889:
<http://rdfdata.org/dha/works_keywords/i1>
rdf:type dha:works_keywords ;
dha:id "1" ;
dha:work <http://rdfdata.org/dha/work/i103> ;
dha:keyword <http://rdfdata.org/dha/keyword/i889> .
RDF lets us do better than this relational database style out-of-line linking. Instead of a “link” resource that references the two linked resources, why not just say in the data about work i103 that it has a keyword of resource i889? The createWorkKeywordTriples.rq query does just that, reading the above triples and creating a new workKeywordTriples.ttl file in the newrdf subdirectory that has triples like this:
dhaw:i103 schema:keywords dhak:i889 .
Once I’ve done that, I don’t even need the triples in the works_keywords.ttl file. They’re just an artifact of the data’s relational heritage. I also used the schema.org standard’s property schema:keywords to show that a given keyword was assigned to a given work. If I’m going to connect keywords to a work the RDF way, I may as well use a property from a well-known standard to do it!
A createWorkTopicTriples.rq SPARQL CONSTRUCT query does the same thing with the topic assignments that createWorkKeywordTriples.rq did with the keyword assignments.
What have we got?
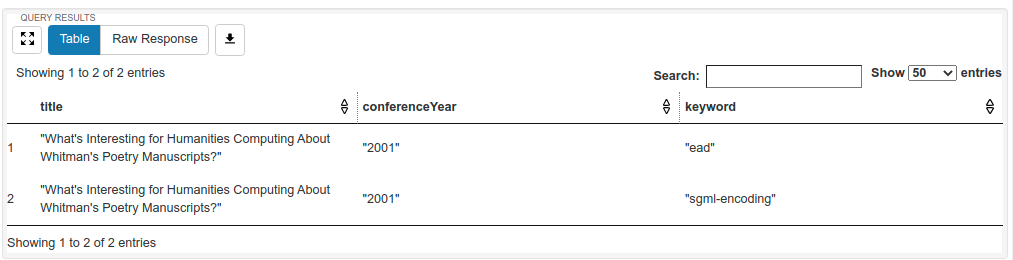
Once we have made these improvements, we can run the following query to ask about the title, conference year, and any keywords associated with any works that mention Whitman in their title:
PREFIX dha: <http://rdfdata.org/dha/ns/dh-abstracts/>
PREFIX schema: <http://schema.org/>
SELECT ?title ?conferenceYear ?keyword WHERE {
?work dha:title ?title ;
dha:conference ?conferenceID ;
schema:keywords ?keywordID .
?keywordID dha:title ?keyword .
FILTER (CONTAINS(?title,"Whitman"))
?conferenceID dha:year ?conferenceYear .
}
There is only one work, but because it has two different keywords assigned to it, the result shows up as two rows:
Next steps
The github repository’s readme file has a step-by-step enumeration of which scripts to run when, with less discussion than you’ve seen here. It also provides a preview of some of the things I’ll talk about next time when I demonstrate some of the things we can do with RDF versions of this data that we can’t do (or at least, can’t do nearly as easily) with the relational version.
Comments? Reply to my tweet announcing this blog entry.


Share this post