Trying out Blazegraph
Especially inferencing.
I’ve been hearing more about the Blazegraph triplestore (well, “graph database with RDF support”), especially its support for running on GPUs, and because they also advertise some degree of RDFS and OWL support, I wanted to see how quickly I could try that after downloading the community edition. It was pretty quick.
Downloading from the main download page with my Ubuntu machine got me an rpm file, but I found it simpler to download the jar file version that I could start as a server from the command line as described on the Nano SPARQL Server page. I found the jar file (and several other download options) on the sourceforge page for release 2.1.
The jar file’s startup message tells you the URL for the web-based interface to the Nano SPARQL Server, shown here:
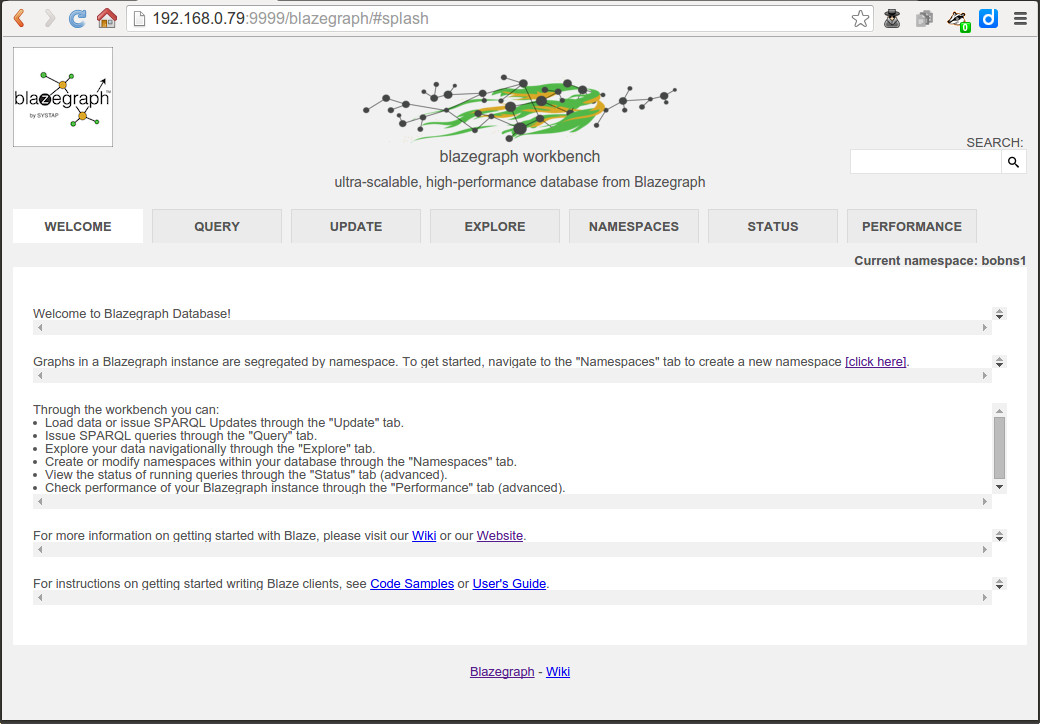
At this point, uploading some RDF on the UPDATE tab and issuing SPARQL queries on the QUERY tab was easy. I was more interested sending it SPARQL queries that could take advantage of RDFS and OWL inferencing, so after a little help from Blazegraph Chief Scientist Bryan Thompson via their mailing list (with a quick answer on a Saturday) I learned how: I had to first create a namespace on the NAMESPACES tab with the Inference checkbox checked. The same form also offers checkboxes for Isolatable indexes, Full text index, and Enable geospatial when configuring a new namespace. I found this typical of how Blazegraph lets you configure it to take advantage of more powerful features while leaving the out-of-box configuration simple and easy to use.
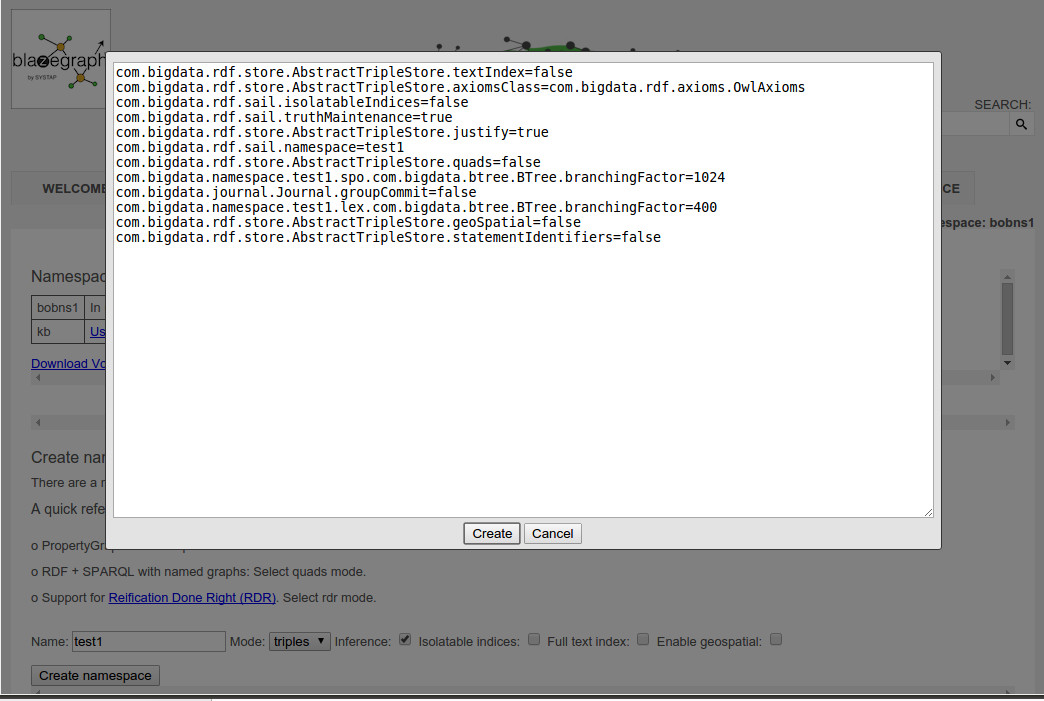
For finer-grained namespace configuration, after you select checkboxes and click the Create namespace button, a dialog box lets you edit the configuration details, with each of these lines explained in the Blazegraph documentation:
I wanted to check Blazegraph’s support for owl:TransitiveProperty, because this is such a basic, useful OWL class, as well as its ability to do subclass inferencing. I created some data about chairs, desks, rooms, and buildings, specifying which chairs and desks were in which rooms and which rooms were in which buildings, and also made dm:locatedIn a transitive property:
@prefix d: <http://learningsparql.com/ns/data#> .
@prefix dm: <http://learningsparql.com/ns/demo#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
dm:Room rdfs:subClassOf owl:Thing .
dm:Building rdfs:subClassOf owl:Thing .
dm:Furniture rdfs:subClassOf owl:Thing .
dm:Chair rdfs:subClassOf dm:Furniture .
dm:Desk rdfs:subClassOf dm:Furniture .
dm:locatedIn a owl:TransitiveProperty.
d:building100 rdf:type dm:Building .
d:building200 rdf:type dm:Building .
d:room101 rdf:type dm:Room ; dm:locatedIn d:building100 .
d:room102 rdf:type dm:Room ; dm:locatedIn d:building100 .
d:room201 rdf:type dm:Room ; dm:locatedIn d:building200 .
d:room202 rdf:type dm:Room ; dm:locatedIn d:building200 .
d:chair15 rdf:type dm:Chair ; dm:locatedIn d:room101 .
d:chair23 rdf:type dm:Chair ; dm:locatedIn d:room101 .
d:chair35 rdf:type dm:Chair ; dm:locatedIn d:room202 .
d:desk22 rdf:type dm:Desk ; dm:locatedIn d:room101 .
d:desk59 rdf:type dm:Desk ; dm:locatedIn d:room202 .
The following query asks for furniture in building 100. No triples above will match either of the query’s two triple patterns, so a SPARQL engine that can’t do inferencing won’t return anything. I wanted the query engine to infer that if chair 15 is a Chair, and Chair is a subclass of Furniture, then chair 15 is Furniture; also, if that furniture is in room 101 and room 101 is in building 100, then that furniture is in building 100.
PREFIX dm: <http://learningsparql.com/ns/demo#>
PREFIX d: <http://learningsparql.com/ns/data#>
SELECT ?furniture
WHERE
{
?furniture a dm:Furniture .
?furniture dm:locatedIn d:building100 .
}
We need the first triple pattern because the data above includes triples saying that rooms 101 and 102 are located in building 100, so those would have bound to ?furniture in the second triple pattern if the first triple pattern wasn’t there. This is a nice example of why declaring resources as instances of specific classes, while not necessary in RDF, does a favor to anyone who will query that data—it makes it easier for them to specify more detail about exactly what data they want.
When using this query and data in a namespace (in the Blazegraph sense of the term) configured to do inferencing, Blazegraph executed the query against the original triples plus the inferred triples and listed the furniture in building 100:
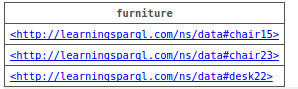
Several years ago I backed off from discussions of the “semantic web” as a buzzphrase tying together technology around RDF-related standards because I felt that the phrase was not aging well and that the technology could be sold on its own without the buzzphrase, but the example above really does show semantics at work. Saying that dm:locatedIn is a transitive property stores some semantics about that property, and these extra semantics let me get more out of the data set: they let me query for which furniture is in which building, even though the data has no explicit facts about furniture being in buildings. (Saying that Desk and Chair are subclasses of Furniture also stores semantics about all three terms, but that won’t be as interesting to a typical developer with object-oriented experience.)
Blazegraph calls their subset of OWL RDFS+, which was inspired by Jim Hendler and Dean Allemang’s RDFS+ superset of RDF that added in OWL’s most useful bits. (It’s similar but not identical to AllegroGraph’s RDFS++ profile, which has the same goal.) Blazegraph’s Product description page describes which parts of OWL it supports, and their Inference And Truth Maintenance page describes more.
A few other interesting things about Blazegraph as a triplestore and query engine:
-
The REST interface offers access to a wide range of features.
-
Queries can include Query Hints to optimize how the SPARQL engine executes them, which will be handy if you plan on scaling way up.
-
I saw no no direct references to GeoSPARQL in the Blazegraph documentation, but they recently announced support for geospatial SPARQL queries. (I’ve been learning a lot about working with geospatial data at Hadoop scale with GeoMesa.)
Blazegraph’s main selling points seems to be speed and scalability (for example, see its Scaleout Cluster mode) and I didn’t play with those at all, but I liked seeing that SPARQL querying with inferencing support can take advantage of such new hotness technology as GPUs. It will be interesting to see where Blazegraph takes it.


Share this post